This FFSVC20 challenge database is provided by AISHELL , which has released multiple open source databases, namelyAISHELL 1 , AISHELL 2 and HI-MIA.
This FFSVC20 challenge database is part of the AISHELL Distributed Microphone Arrays in Smart Home (DMASH) Database. The recording devices include one close-talking microphone (48kHz, 16 bit), one cellphone (48kHz, 16 bit) at 25cm distance and multiple circular microphone arrays (16kHz, 16bit, 4 out of 16 microphones, 5cm radius). The language is Chinese Mandarin. Text content include 'ni hao, mi ya' as text dependent utterances as well as other text independent ones.
The data collection setup is shown in Fig 1.Red arrow points to channel 0 of microphone arrays.
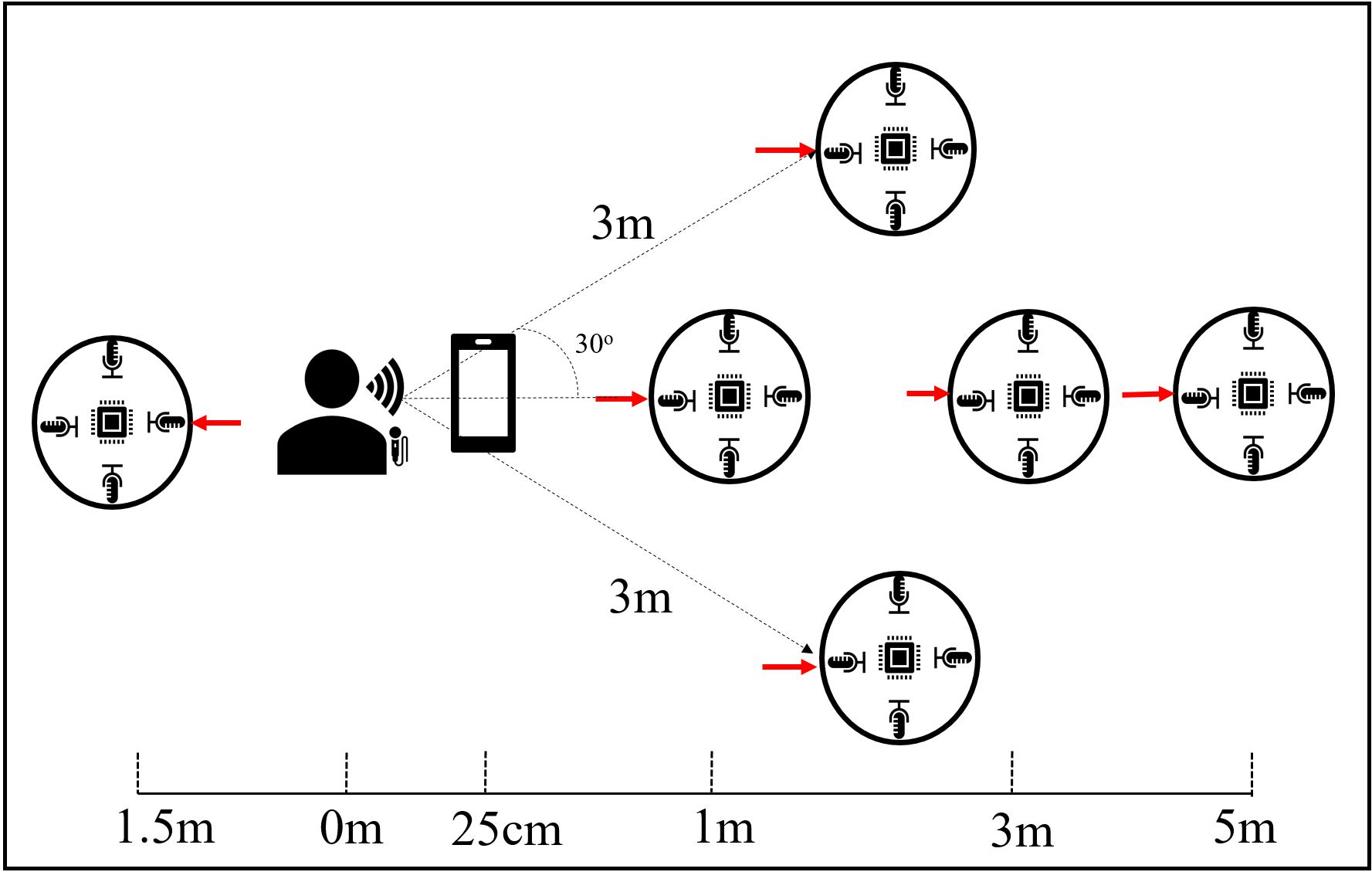
Figure1 The setup of the challenge database
Each speaker visit 3 times with 7-15 days gap.
The HI-MIA database includes two sub databases, which are the AISHELL- wakeup1 with 254 speakers and the AISHELL-2019B-eval with 86 speakers. The HIMIA_FFSVC2020_overlap.txt contains the list of speakers that overlap between the HIMIA dataset and our challenge data.
The content of utterances is “ni hao, mi ya”(“你 好, 米 雅”) ’ in Mandarin. The HI-MIA database served as the benchmark data for AISHELL Speaker Verification Challenge 2019. Click here to download the HI-MIA dataset and dataset description.
Since the original audio name format of the HI-MIA database is a little bit confusing, we provide a new version of the label files (train_rename.scp and dev_rename.scp for Hi-MIA). Click here to download.
Since the audio files in the HI-MIA test set is not strictly synchronized , different channels of the same device may have slightly different audio lengths. The original synchronized test data can be downloaded here For the training and development set of HI-MIA, all channels from each microphone array are synchronized.